html문서가 아닌 json 형태로 정보를 전달하는 api에서 크롤링하기 위한 방법에 대해 배워보자.
API에 접근하기 위해선 우회를 해줘야한다. 이를 우회하기 위해서 요청시에 headers 매개변수를 지정한다.
1. headers 옵션
custom_header = {
'referer':... # 이전 웹페이지의 주소
'user-agent': ... # 이용자의 여러가지 사양 ex) 브라우저 os
}
req = requests.get(url, headers = custom_header)
2. api 확인하기
사용된 api를 확인하는 방법에 대해 알아보자.
finance.daum.net/ 다음 증권사 페이지에 들어가서 상위 10개 기업을 크롤링하고자 한다.
api를 확인하기 위해선
f12를 눌러 개발자 모드를 켜고 network탭에 들어간다.
그리고 하단에 돋보기를 눌러 텍스트를 검색한다.
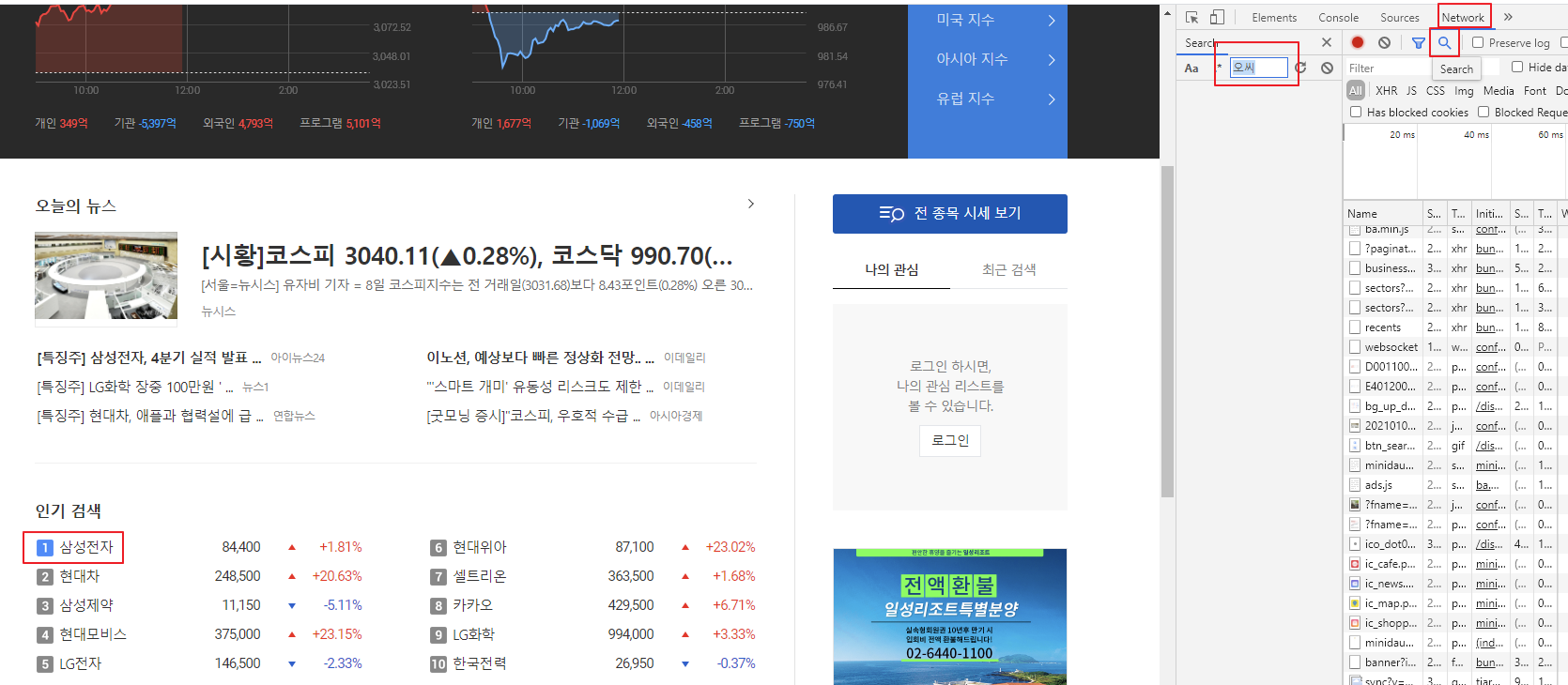
샘숭을 검색해본다.

filter에 ranks라고 쳐도 저게 나온다.
암튼 헤더란에 들어가면 http 헤더가 나오고 거기서 url을 확인하면 된다.

preview란을 보면 전체 데이터가 나온다.
data객체 안에 여러 개의 json객체가 있음을 알 수 있다.
저 데이터를 파이썬 객체로 사용하기 위해선 json.loads를 사용해야 한다.
cf_ 파이썬 객체를 json으로 바꾸는 것은 json.dumps이다.
data = json.loads(req.text)
# loads: json 텍스트를 파이썬 객체로 역직렬화
실습1
import requests
import json
custom_header = {
'referer' : 'http://http://finance.daum.net/quotes/A048410#home',
'user-agent' : 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36' }
def get_data() :
result = []
url = "http://finance.daum.net/api/search/ranks?limit=10" # 상위 10개 기업의 정보를 얻는 API url을 작성하세요.
req = requests.get(url, headers = custom_header)
if req.status_code == requests.codes.ok:
print("접속 성공")
txt = json.loads(req.text)
for data in txt['data']:
tup = (data['rank'], data['name'], data['tradePrice'])
result.append(tup)
else:
print("접속 실패")
return result
def main() :
data = get_data()
for d in data :
print(d)
if __name__ == "__main__" :
main()
실습2
특정 검색어를 입력하면, 해당 검색어에 관련된 음식점들의 리뷰 상위 5개를 각각 찾아 출력한다.
from bs4 import BeautifulSoup
import requests
import json
custom_header = {
'referer' : 'https://www.mangoplate.com/',
'user-agent' : 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36' }
def get_reviews(code) :
comments = []
url = f"https://stage.mangoplate.com/api/v5{code}/reviews.json?language=kor&device_uuid=V3QHS15862342340433605ldDed&device_type=web&start_index=0&request_count=5&sort_by=2"
req = requests.get(url, headers = custom_header)
# 받아온 하이퍼 링크로 api를 요청해서 리뷰에 해당하는 json 정보를 받아온다.
reviews = json.loads(req.text)
for r in reviews:
coms = r['comment']
com = coms['comment'].replace('\n', '')
comments.append(com)
return comments
def get_restaurants(name) :
url = f"https://www.mangoplate.com/search/{name}"
req = requests.get(url, headers = custom_header)
soup = BeautifulSoup(req.text, "html.parser")
# 검색결과에 해당하는 페이지에서 식당이름과 해당 식당의 하이퍼링크를 받아온다.
res_list = []
restaurants = soup.find_all('div', class_='list-restaurant-item')
for r in restaurants:
info = r.find('div', class_='info')
href = info.find('a')['href']
title = info.find('h2').get_text().replace('\n', '')
res_list.append((title, href))
return res_list
def main() :
name = input("검색어를 입력하세요 : ")
restuarant_list = get_restaurants(name)
# 검색결과에 해당하는 식당 이름 10개와 하이퍼링크를 불러온다.
for r in restuarant_list :
print(r[0])
print(get_reviews(r[1]))
print("="*30)
print("\n"*2)
if __name__ == "__main__" :
main()
'Data Science > Data Science' 카테고리의 다른 글
| [Data Science] 데이터 형변환 (0) | 2021.01.17 |
|---|---|
| [Data Science] 텍스트 파일 분석 (2) | 2021.01.12 |
| [Data Science] 파이썬 크롤링 - 워드 클라우드 만들기 (0) | 2021.01.12 |
| [Data Science] 파이썬 크롤링 2 (0) | 2021.01.07 |
| [Data Science] 파이썬 크롤링 (0) | 2021.01.06 |


댓글